Hugging Face 该最新系列包括 H2O-Danube3-4B 和紧凑型 H2O-Danube3-500M 型号。H2O-Danube3-4B 训练了 6 万亿个 token,而 H2O-Danube3-500M 训练了 4 万亿个 token,旨在处理大量数据集,并针对多种应用进行了微调。这些模型经过精心设计,效率高到足以在现代智能手机上运行,从而将先进的 NLP 功能带给大众。

H2O Danube3-4B 模型在 10 次 #HellaSwag 基准测试中取得了超过 80% 的令人印象深刻的分数,超越了 #AppleLLM OpenELM-3B-Instruct 并与 Microsoft Phi3 4B 相媲美。
此外,与阿里巴巴 Qwen2-0.5B 和苹果 OpenELM-0.5B-Instruct 等类似规模的模型相比,H2O-Danube3-500M 模型在 12 个学术基准测试中的 7 个中得分最高,表现出色。
这些模型体现了非凡的多功能性和效率,使其非常适合各种应用,包括聊天机器人、研究和移动设备解决方案。


由 H2O Danube 提供支持的移动应用程序
H2O AI个人GPT

- 内容生成:在飞行模式下写作和编辑。
- 研究:以离线模式进行分析和学习。在困顿时获取关键信息。
- 护栏和网关:在发送到更昂贵的模型之前,确认用户的问题和输入是有效和安全的。
- 娱乐:阅读流行文化琐事、了解历史事实、创建社交内容日历。
- 远程现场工作(物联网): 即使在服务中断期间,技术人员也可以从现场移动设备上的物联网传感器获取数据。
https://h2o.ai/platform/danube
2.1 论文的背景
小型语言模型在当今的开源语言模型领域占据关键地位,特别针对在消费者硬件和边缘设备上的高效推理,同时支持完全离线应用。此外,经过特定任务微调后的小型模型已被证明特别有用,例如序列分类、问答或token分类,甚至超越了先前使用的编码器/解码器模型,如源自 BERT 及其衍生模型。
论文在该领域的先前研究基础上,提出 H2O-Danube3,一系列小型语言模型,包括 H2O-Danube3-4B,训练于 6T token,以及 H2O-Danube3-500M,训练于4 T token,基于持续的研究和训练努力 。在本报告中,论文概述了这些模型,详细介绍了它们的架构、训练过程和微调流程。论文通过多样化的基准测试进行了广泛评估,涵盖标准学术指标、聊天基准和微调基准。
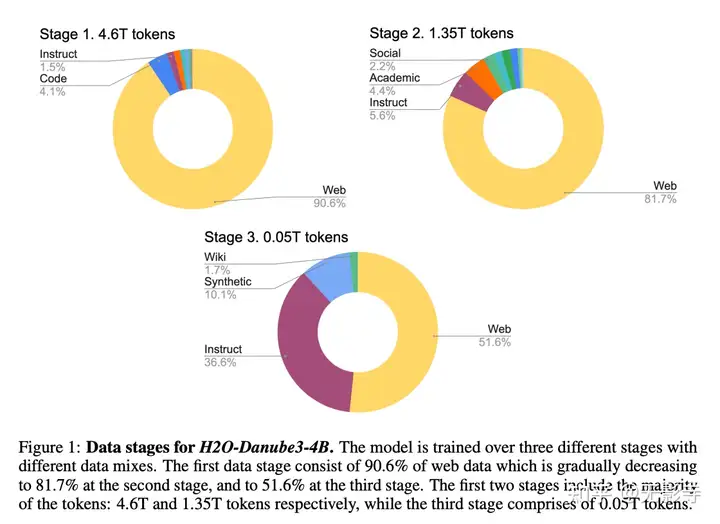
图1:H20-Danube3-4B的数据阶段。模型在三个不同阶段使用不同的数据混合进行训练。第一阶段包含90.6%的网络数据,第二阶段的81.7%,第三阶段的51.6%。前两个阶段包含大部分的token:分别为4.6T和1.35Ttoken,而第三阶段包含0.05Ttoken
2.2 模型架构
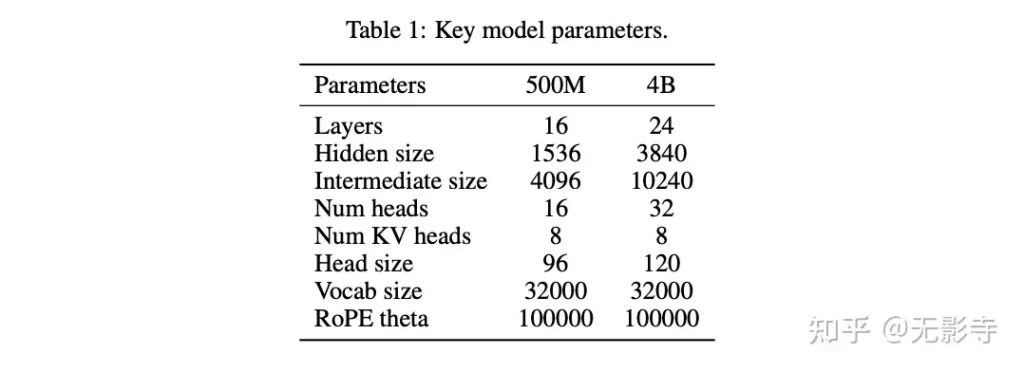
H2O-Danube3是一系列仅解码器的LLM模型,采用Llama模型架构的核心原则,借鉴了Llama 2 和Mistral ,并通过自定义参数确定每层的形状和总参数数量。论文使用词汇量为32,000的Mistral分词器,并将模型训练至上下文长度为8,192。论文采用Grouped Query Attention ,并优化参数和计算效率,形成宽架构(见表1)。总计,H20-Danube3-4B包含39.6亿可训练参数。此外,论文还发布了H2O-Danube3-500M,包含5亿可训练参数,适用于计算资源有限的边缘设备或需要低内存占用或低成本高吞吐量的定制微调任务。
表1:关键模型参数
2.3 训练
模型主要在三个阶段使用不同数据混合的英语文本进行训练。在每个阶段,论文逐渐减少噪声网络数据的百分比,以支持更高质量的数据:
第一阶段包含90.6%的网络数据,第二阶段逐渐减少至81.7%,第三阶段的51.6%。
同时,指令数据、维基百科、学术文本、合成文本和其他高质量文本数据的份额在增加。
前两个阶段包含大部分的token:分别为4.67T和1.357Ttoken(H2O-Danube3-500M为2.87T和1.157T token),而第三阶段包含0.05T token。各阶段的数据分布如图1所示。
论文还提供了经过聊天微调的版本H2O-Danube3-4B-Chat和H2O-Danube3-500M-Chat。论文利用H2O LLM Studio,这是一个Apache 2.0开源框架和无需编码的图形用户界面(GUI),用于微调大型语言模型(LLMs)。论文通过在输入/输出对话对上进行监督微调(SFT)来调整基础模型。论文屏蔽了提示损失,并使用了自定义提示格式。通过多次实验迭代优化了超参数。
2.4 评估
在本节中,论文展示了H20-Danube3在多个维度上的评估结果,重点关注(1)学术基准测试,(2)聊天基准测试和(3)微调基准测试。
学术基准测试。论文在广泛的基准测试中评估H2O-Danube3,并将其与其他现有的具有相似参数数量的开源语言模型进行比较,特别是Qwen/Qwen1.5-4B-Chat、stabilityai/stablelm-zephyr-3b和microsoft/Phi-3-mini-4k-instruct。论文还与之前的模型h2oai/h2o-danube2-1.8b-chat进行比较。
为了评估模型,论文使用了Language Model Evaluation Harness框架 。H20-Danube3-4B在所有报告的基准测试中显示出非常具有竞争力且一致的结果(见表2)。它是知识型基准测试CommonsenseQA和PhysicsQA的最佳模型,并在以数学为中心的基准测试GSM8K上达到了50.149%的强大准确率。在所有其他基准测试中,H2O-Danube3-4B仅次于以出色推理能力和强基准分数著称的Phi-3-mini-4k-instruct。
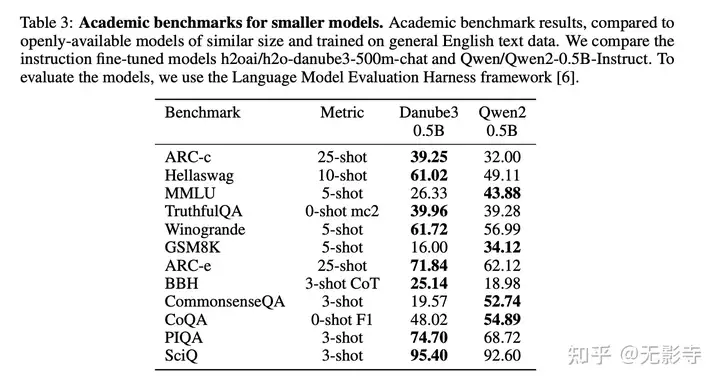
值得注意的是,H2O-Danwbe3-4B在10次迭代的hellaswag基准测试中得分超过80%,缩小了与更大模型的差距。较小的H2O-Danube3-500M在相同的基准测试中进行评估,并与类似大小的Qwen2-0.5B-Instruct进行比较(见表3)。论文的模型在十二个基准测试中八个得分最高,论文认为它是这一参数数量下的全新全能模型。
表2:学术基准测试。学术基准测试结果,与公开可用、规模相似且基于通用英语文本数据训练的模型进行比较。论文比较了指令微调模型h2oai/h2o-danube2-1.8b-chat、h2oai/h2o-danube3-4b-chat、Qwen/Qwen1.5-4B-Chat、stabilityai/stablelm-zephyr-3b、microsoft/Phi-3-mini-4k-instruct。为了评估这些模型,论文使用了语言模型评估框架[6]
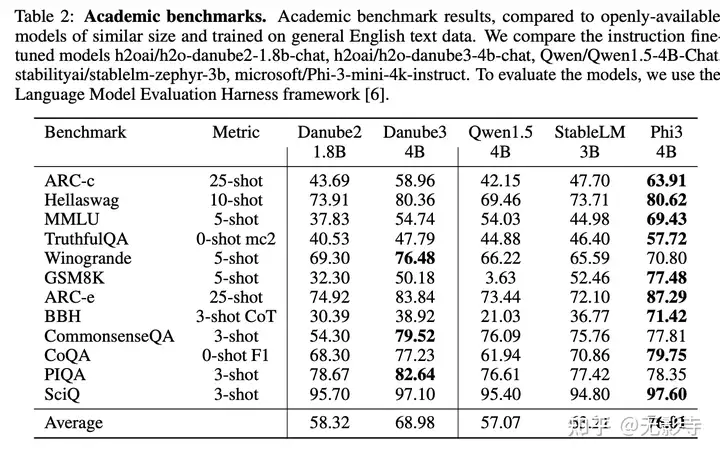
表3:小型模型的学术基准测试。学术基准测试结果,与公开可用、规模相似且基于通用英语文本数据训练的模型进行比较。论文比较了指令微调模型h2oai/h2o-danube3-500m-chat和Qwen/Qwen2-0.5B-Instruct。为了评估这些模型,论文使用了语言模型评估框架[6]。
聊天基准测试。评估聊天和指令微调的大型语言模型(LLMs)仍然是一个关键挑战,最可靠的方法是通过大规模的人类评估。为了初步评估论文的聊天模型,论文采用了MT-Bench 和WilaBench-v2 基准测试。这些基准测试包含跨不同类别的多轮问题,并由GPT-4进行评判,为每个模型的响应分配1到10的分数。
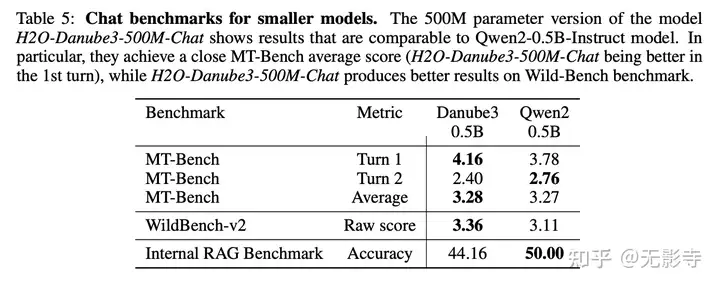
结果显示在表4中,表明H2O-Danube3-4B-Chat超越了其他类似规模的模型,而Phi-3-mini则位居榜首。500M参数版本的模型H2O-Danube3-500M-Chat显示出与Qwen2-0.5B-Instruct相当的结果(见表5)。
论文额外进行了多项内部评估,并将结果展示在相同的表格中。首先,论文按照“Chat Arena”的理念,对聊天性能(不包括500M模型)进行了盲测评估。这涉及向用户展示随机配对的模型,允许他们进行提示并投票选择输出偏好(A更好,B更好,两者都差,两者都好),随后使用MLE和bootstrap方法计算ELO分数。其次,论文利用内部RAG(检索增强生成)基准来评估模型在基于长PDF文档的问答任务中的表现。论文通过比较模型生成的回答与标准答案来计算每个模型的准确率分数。
表格4:聊天基准测试。H2O-Danube3-4B-Chat在所有基准测试中表现非常出色,超越了其他类似规模的模型,并优于论文之前的Danube2版本,而Phi-3-mini则位居榜首。
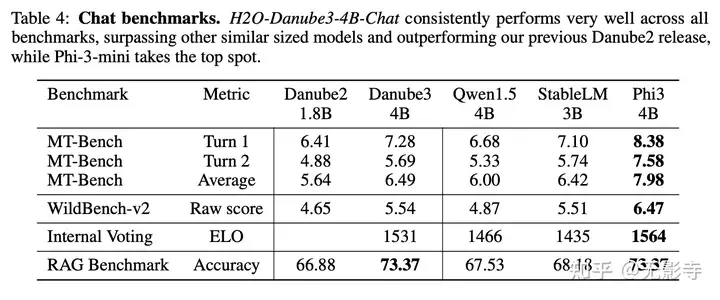
表格5:小型模型的聊天基准测试。500M参数版本的H2O-Danube3-500M-Chat模型的结果与Qwen2-0.5B-Instruct模型相当。特别是,它们在MT-Bench平均得分上非常接近(H2O-Danube3-500M-Chat在第一轮表现更佳),而H2O-Danube3-500M-Chat在Wild-Bench基准测试中表现更优。
微调基准测试。小型语言模型的一个常见应用是针对各种用例进行微调,以优化其在特定任务上的性能。为此,论文还评估了不同模型易于适应新任务的能力,这里主要关注在企业和应用中广泛观察到的文本分类任务。
论文采用以下流程进行微调基准测试。论文利用H2O LLM Studio提供的开箱即用的语言模型分类微调功能,通过自定义分类头输入最终的token logit分布进行分类。对于所有模型和数据集,论文使用相同的设置(LoRA (r = 16, a = 32))和相同的超参数(bs = 1, epochs = 1, Ir = le – 4, dif f Ir = 1e – 05, maw length = 8192)。这些设置是该领域的常用默认设置,论文的目标是特别评估模型微调后的默认性能。论文考察以下数据集,这些数据集都可以在Hugging Face上找到:
- stanfordnlp/imdb: IMDb电影评论的二元句子分类
- knowledgator/Scientific-text-classification: 将科学文本分类为10个最频繁类别,随机50-50分割
- ccdv/arxiv-classification: 将arXiv论文的长上下文分类为11个类别
- ccdv/patent-classification: 将专利的长上下文分类为9个类别
表6突出显示了各个数据集和模型的结果,论文始终报告最高概率类别的准确率。可以看出,所有小型语言模型在微调后在文本分类任务上都表现出优异的性能。即使是5亿参数的小模型也能极具竞争力,这证明了针对特定用例微调这些模型的实用性。
总体而言,H2O-Danube3-4B在所有基准测试中占据领先地位。这些结果可以作为基于默认超参数设置的基线结果。更广泛的参数扫描可能会潜在地提高所有模型的结果,并可能改变性能顺序。论文计划在未来更广泛地研究这种微调性能。
表6:微调基准测试。所有模型在经过微调后,在各种分类任务中均表现出色,其中H2O-Danube3-4B在大多数基准测试中名列前茅
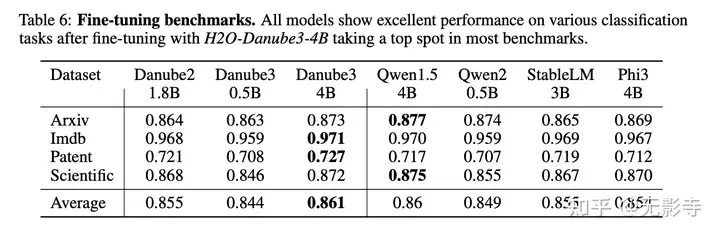
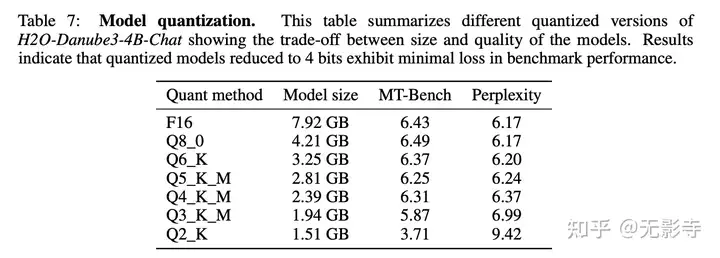
表7:模型量化。此表总结了不同量化版本的H2O-Danube3-4B-Chat,展示了模型大小与质量之间的权衡。结果表明,量化至4位的模型在基准性能上的损失最小。
2.5 模型量化
为了便于在边缘设备上使用论文的模型,论文推出了H2O-Danube3-4B-Chat和H2O-Danube3-500M-Chat的量化版本。它们可在H2O-Danube3的Hugging Face集合中获取,包含使用llama.cpp框架量化的GGUF格式模型文件。
表7总结了H2O-Danube3-4B-Chat的不同量化版本。它展示了不同量化方法在模型大小与质量之间的权衡。表格中的列分别表示量化方法、模型大小(以吉字节为单位)、MT-Bench[16]基准测试得分以及WikiText-2数据集上的困惑度指标(来自llama.cpp的困惑度测试报告)。结果表明,论文可以将模型大小减少3.3倍(4位量化),同时保持模型质量几乎不变,但采用3位量化已显著降低性能。
- LinkAI工作流(WorkFlow) 智能体Agent
- 完美绕过激活解锁信号插卡,GusActivatorPro A12+发布!
- 能在手机上跑的开源小模型 H2O-Danube3
- 大模型的注意力机制
- 聚合多模型平台 AskManyAI