自从 BERT 和 GPT 模型取得重大成功之后, Transformer 结构已经替代了循环神经网络 (RNN) 和卷积神经网络 (CNN),成为了当前 NLP 模型的标配。
起源与发展
2017 年 Google 在《Attention Is All You Need》中提出了 Transformer 结构用于序列标注,在翻译任务上超过了之前最优秀的循环神经网络模型;与此同时,Fast AI 在《Universal Language Model Fine-tuning for Text Classification》中提出了一种名为 ULMFiT 的迁移学习方法,将在大规模数据上预训练好的 LSTM 模型迁移用于文本分类,只用很少的标注数据就达到了最佳性能。
这些具有开创性的工作促成了两个著名 Transformer 模型的出现:
- GPT (the Generative Pretrained Transformer);
- BERT (Bidirectional Encoder Representations from Transformers)。
通过将 Transformer 结构与无监督学习相结合,我们不再需要对每一个任务都从头开始训练模型,并且几乎在所有 NLP 任务上都远远超过先前的最强基准。
GPT 和 BERT 被提出之后,NLP 领域出现了越来越多基于 Transformer 结构的模型,其中比较有名有:
虽然新的 Transformer 模型层出不穷,它们采用不同的预训练目标在不同的数据集上进行训练,但是依然可以按模型结构将它们大致分为三类:
- 纯 Encoder 模型(例如 BERT),又称自编码 (auto-encoding) Transformer 模型;
- 纯 Decoder 模型(例如 GPT),又称自回归 (auto-regressive) Transformer 模型;
- Encoder-Decoder 模型(例如 BART、T5),又称 Seq2Seq (sequence-to-sequence) Transformer 模型。
什么是 Transformer
语言模型
Transformer 模型本质上都是预训练语言模型,大都采用自监督学习 (Self-supervised learning) 的方式在大量生语料上进行训练,也就是说,训练这些 Transformer 模型完全不需要人工标注数据。
自监督学习是一种训练目标可以根据模型的输入自动计算的训练方法。
例如下面两个常用的预训练任务:
- 基于句子的前 n 个词来预测下一个词,因为输出依赖于过去和当前的输入,因此该任务被称为因果语言建模 (causal language modeling);

- 基于上下文(周围的词语)来预测句子中被遮盖掉的词语 (masked word),因此该任务被称为遮盖语言建模 (masked language modeling)。
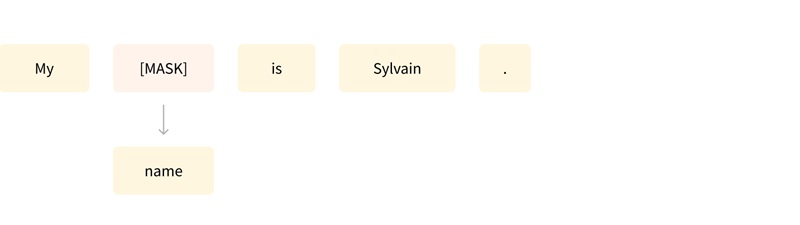
这些语言模型虽然可以对训练过的语言产生统计意义上的理解,例如可以根据上下文预测被遮盖掉的词语,但是如果直接拿来完成特定任务,效果往往并不好。
“因果语言建模”就是统计语言模型,只使用前面的词来预测当前词,由 NNLM 首次运用;而“遮盖语言建模”实际上就是 Word2Vec 模型提出的 CBOW。
因此,我们通常还会采用迁移学习 (transfer learning) 方法,使用特定任务的标注语料,以有监督学习的方式对预训练模型参数进行微调 (fine-tune),以取得更好的性能。
大模型与碳排放
除了 DistilBERT 等少数模型,大部分 Transformer 模型都为了取得更好的性能而不断地增加模型大小(参数量)和增加预训练数据。下图展示了近年来模型大小的变化趋势:
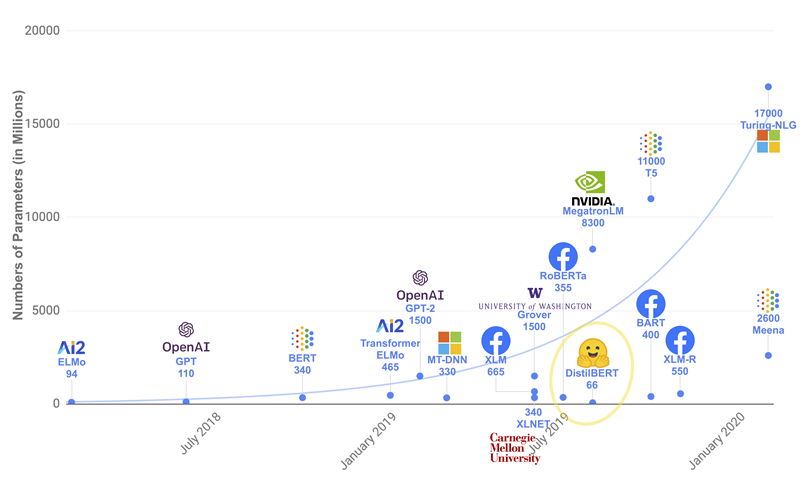
但是,从头训练一个预训练语言模型,尤其是大模型,需要海量的数据,不仅时间和计算成本非常高,对环境的影响也很大:
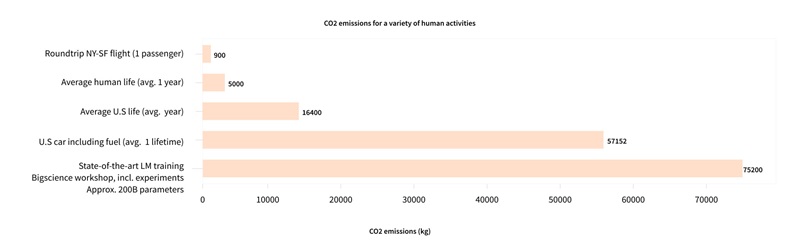
可以想象,如果每一次研究者或是公司想要使用语言模型,都需要基于海量数据从头训练,将耗费巨大且不必要的全球成本,因此共享语言模型非常重要。只要在预训练好的模型权重上构建模型,就可以大幅地降低计算成本和碳排放。
现在也有一些工作致力于在尽可能保持模型性能的情况下大幅减少参数量,达到用“小模型”获得媲美“大模型”的效果(例如模型蒸馏)。
迁移学习
前面已经讲过,预训练是一种从头开始训练模型的方式:所有的模型权重都被随机初始化,然后在没有任何先验知识的情况下开始训练:

这个过程不仅需要海量的训练数据,而且时间和经济成本都非常高。
因此,大部分情况下,我们都不会从头训练模型,而是将别人预训练好的模型权重通过迁移学习应用到自己的模型中,即使用自己的任务语料对模型进行“二次训练”,通过微调参数使模型适用于新任务。
这种迁移学习的好处是:
- 预训练时模型很可能已经见过与我们任务类似的数据集,通过微调可以激发出模型在预训练过程中获得的知识,将基于海量数据获得的统计理解能力应用于我们的任务;
- 由于模型已经在大量数据上进行过预训练,微调时只需要很少的数据量就可以达到不错的性能;
- 换句话说,在自己任务上获得优秀性能所需的时间和计算成本都可以很小。
例如,我们可以选择一个在大规模英文语料上预训练好的模型,使用 arXiv 语料进行微调,以生成一个面向学术/研究领域的模型。这个微调的过程只需要很少的数据:我们相当于将预训练模型已经获得的知识“迁移”到了新的领域,因此被称为迁移学习。
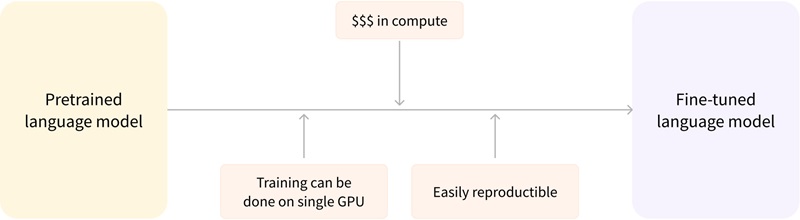
与从头训练相比,微调模型所需的时间、数据、经济和环境成本都要低得多,并且与完整的预训练相比,微调训练的约束更少,因此迭代尝试不同的微调方案也更快、更容易。实践证明,即使是对于自定义任务,除非你有大量的语料,否则相比训练一个专门的模型,基于预训练模型进行微调会是一个更好的选择。
在绝大部分情况下,我们都应该尝试找到一个尽可能接近我们任务的预训练模型,然后微调它,也就是所谓的“站在巨人的肩膀上”。
Transformer 的结构
标准的 Transformer 模型主要由两个模块构成:
- Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征);
- Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。
这两个模块可以根据任务的需求而单独使用:
- 纯 Encoder 模型:适用于只需要理解输入语义的任务,例如句子分类、命名实体识别;
- 纯 Decoder 模型:适用于生成式任务,例如文本生成;
- Encoder-Decoder 模型或 Seq2Seq 模型:适用于需要基于输入的生成式任务,例如翻译、摘要。
注意力层
Transformer 模型的标志就是采用了注意力层 (Attention Layers) 的结构,前面也说过,提出 Transformer 结构的论文名字就叫《Attention Is All You Need》。顾名思义,注意力层的作用就是让模型在处理文本时,将注意力只放在某些词语上。
例如要将英文“You like this course”翻译为法语,由于法语中“like”的变位方式因主语而异,因此需要同时关注相邻的词语“You”。同样地,在翻译“this”时还需要注意“course”,因为“this”的法语翻译会根据相关名词的极性而变化。对于复杂的句子,要正确翻译某个词语,甚至需要关注离这个词很远的词。
同样的概念也适用于其他 NLP 任务:虽然词语本身就有语义,但是其深受上下文的影响,同一个词语出现在不同上下文中可能会有完全不同的语义(例如“我买了一个苹果”和“我买了一个苹果手机”中的“苹果”)。
我们在上一章中已经讨论过多义词的问题,这也是 Word2Vec 这些静态模型所解决不了的。
原始结构
Transformer 模型本来是为了翻译任务而设计的。在训练过程中,Encoder 接受源语言的句子作为输入,而 Decoder 则接受目标语言的翻译作为输入。在 Encoder 中,由于翻译一个词语需要依赖于上下文,因此注意力层可以访问句子中的所有词语;而 Decoder 是顺序地进行解码,在生成每个词语时,注意力层只能访问前面已经生成的单词。
例如,假设翻译模型当前已经预测出了三个词语,我们会把这三个词语作为输入送入 Decoder,然后 Decoder 结合 Encoder 所有的源语言输入来预测第四个词语。
实际训练中为了加快速度,会将整个目标序列都送入 Decoder,然后在注意力层中通过 Mask 遮盖掉未来的词语来防止信息泄露。例如我们在预测第三个词语时,应该只能访问到已生成的前两个词语,如果 Decoder 能够访问到序列中的第三个(甚至后面的)词语,就相当于作弊了。
原始的 Transformer 模型结构如下图所示,Encoder 在左,Decoder 在右:
其中,Decoder 中的第一个注意力层关注 Decoder 过去所有的输入,而第二个注意力层则是使用 Encoder 的输出,因此 Decoder 可以基于整个输入句子来预测当前词语。这对于翻译任务非常有用,因为同一句话在不同语言下的词语顺序可能并不一致(不能逐词翻译),所以出现在源语言句子后部的词语反而可能对目标语言句子前部词语的预测非常重要。
在 Encoder/Decoder 的注意力层中,我们还会使用 Attention Mask 遮盖掉某些词语来防止模型关注它们,例如为了将数据处理为相同长度而向序列中添加的填充 (padding) 字符。
Transformer 家族
虽然新的 Transformer 模型层出不穷,但是它们依然可以被归纳到以下三种结构中:
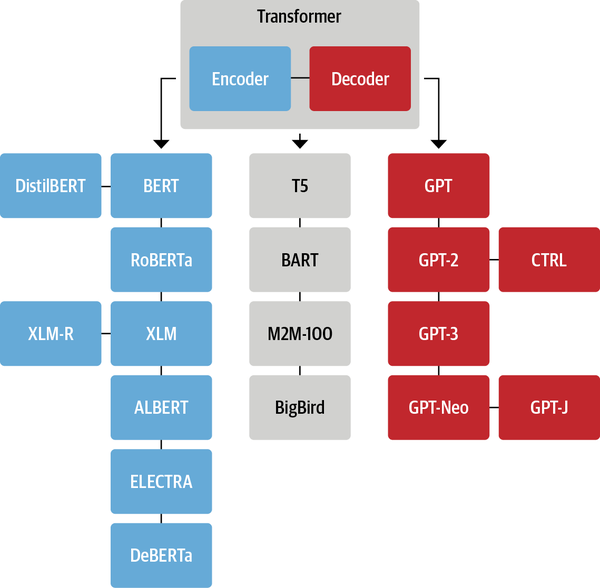
Encoder 分支
纯 Encoder 模型只使用 Transformer 模型中的 Encoder 模块,也被称为自编码 (auto-encoding) 模型。在每个阶段,注意力层都可以访问到原始输入句子中的所有词语,即具有“双向 (Bi-directional)”注意力。
纯 Encoder 模型通常通过破坏给定的句子(例如随机遮盖其中的词语),然后让模型进行重构来进行预训练,最适合处理那些需要理解整个句子语义的任务,例如句子分类、命名实体识别(词语分类)、抽取式问答。
BERT 是第一个基于 Transformer 结构的纯 Encoder 模型,它在提出时横扫了整个 NLP 界,在流行的 GLUE 基准上超过了当时所有的最强模型。随后的一系列工作对 BERT 的预训练目标和架构进行调整以进一步提高性能。目前,纯 Encoder 模型依然在 NLP 行业中占据主导地位。
下面简略介绍一下 BERT 模型及它的常见变体:
- BERT:通过预测文本中被遮盖的词语和判断一个文本是否跟随另一个来进行预训练,前一个任务被称为遮盖语言建模 (Masked Language Modeling, MLM),后一个任务被称为下句预测 (Next Sentence Prediction, NSP);
- DistilBERT:尽管 BERT 性能优异,但它的模型大小使其难以部署在低延迟需求的环境中。 通过在预训练期间使用知识蒸馏 (knowledge distillation) 技术,DistilBERT 在内存占用减少 40%、计算速度提高 60% 的情况下,依然可以保持 97% 的性能;
- RoBERTa:BERT 之后的一项研究表明,通过修改预训练方案可以进一步提高性能。 RoBERTa 在更多的训练数据上,以更大的批次训练了更长的时间,并且放弃了 NSP 任务。与 BERT 模型相比,这些改变显著地提高了模型的性能;
- XLM:跨语言语言模型 (XLM) 探索了构建多语言模型的多个预训练目标,包括来自 GPT 的自回归语言建模和来自 BERT 的 MLM,还将 MLM 拓展到多语言输入,提出了翻译语言建模 (Translation Language Modeling, TLM)。XLM 在多个多语言 NLU 基准和翻译任务上都取得了最好的性能;
- XLM-RoBERTa:跟随 XLM 和 RoBERTa,XLM-RoBERTa (XLM-R) 通过升级训练数据来改进多语言预训练。其基于 Common Crawl 创建了一个 2.5 TB 的语料,然后运用 MLM 训练编码器,由于没有平行对照文本,因此移除了 XLM 的 TLM 目标。最终,该模型大幅超越了 XLM 和多语言 BERT 变体;
- ALBERT:ALBERT 通过三处变化使得 Encoder 架构更高效:首先将词嵌入维度与隐藏维度解耦以减少模型参数;其次所有模型层共享参数;最后将 NSP 任务替换为句子排序预测(判断句子顺序是否被交换)。这些变化使得可以用更少的参数训练更大的模型,并在 NLU 任务上取得了优异的性能;
- ELECTRA:MLM 在每个训练步骤中只有被遮盖掉词语的表示会得到更新。ELECTRA 使用了一种双模型方法来解决这个问题:第一个模型继续按标准 MLM 工作;第二个模型(鉴别器)则预测第一个模型的输出中哪些词语是被遮盖的,这使得训练效率提高了 30 倍。下游任务使用时,鉴别器也参与微调;
- DeBERTa:DeBERTa 模型引入了两处架构变化。首先将词语的内容与相对位置分离,使得自注意力层 (Self-Attention) 层可以更好地建模邻近词语对的依赖关系;此外在解码头的 softmax 层之前添加了绝对位置嵌入。DeBERTa 是第一个在 SuperGLUE 基准上击败人类的模型。
Decoder 分支
纯 Decoder 模型只使用 Transformer 模型中的 Decoder 模块。在每个阶段,对于给定的词语,注意力层只能访问句子中位于它之前的词语,即只能迭代地基于已经生成的词语来逐个预测后面的词语,因此也被称为自回归 (auto-regressive) 模型。
纯 Decoder 模型的预训练通常围绕着预测句子中下一个单词展开。纯 Decoder 模型适合处理那些只涉及文本生成的任务。
对 Transformer Decoder 模型的探索在在很大程度上是由 OpenAI 带头进行的,通过使用更大的数据集进行预训练,以及将模型的规模扩大,纯 Decoder 模型的性能也在不断提高。
下面就简要介绍一些常见的生成模型:
- GPT:结合了 Transformer Decoder 架构和迁移学习,通过根据上文预测下一个单词的预训练任务,在 BookCorpus 数据集上进行了预训练。GPT 模型在分类等下游任务上取得了很好的效果;
- GPT-2:受简单且可扩展的预训练方法的启发,OpenAI 通过扩大原始模型和训练集创造了 GPT-2,它能够生成篇幅较长且语义连贯的文本;
- CTRL:GPT-2 虽然可以根据模板 (prompt) 续写文本,但是几乎无法控制生成序列的风格。条件 Transformer 语言模型 (Conditional Transformer Language, CTRL) 通过在序列开头添加特殊的“控制符”以控制生成文本的风格,这样只需要调整控制符就可以生成多样化的文本;
- GPT-3:将 GPT-2 进一步放大 100 倍,GPT-3 具有 1750 亿个参数。除了能生成令人印象深刻的真实篇章之外,还展示了小样本学习 (few-shot learning) 的能力。这个模型目前没有开源;
- GPT-Neo / GPT-J-6B:由于 GPT-3 没有开源,因此一些旨在重新创建和发布 GPT-3 规模模型的研究人员组成了 EleutherAI,训练出了类似 GPT 的 GPT-Neo 和 GPT-J-6B 。当前公布的模型具有 1.3、2.7、60 亿个参数,在性能上可以媲美较小版本的 GPT-3 模型。
Encoder-Decoder 分支
Encoder-Decoder 模型(又称 Seq2Seq 模型)同时使用 Transformer 架构的两个模块。在每个阶段,Encoder 的注意力层都可以访问初始输入句子中的所有单词,而 Decoder 的注意力层则只能访问输入中给定词语之前的词语(即已经解码生成的词语)。
Encoder-Decoder 模型可以使用 Encoder 或 Decoder 模型的目标来完成预训练,但通常会包含一些更复杂的任务。例如,T5 通过随机遮盖掉输入中的文本片段进行预训练,训练目标则是预测出被遮盖掉的文本。Encoder-Decoder 模型适合处理那些需要根据给定输入来生成新文本的任务,例如自动摘要、翻译、生成式问答。
下面简单介绍一些在自然语言理解 (NLU) 和自然语言生成 (NLG) 领域的 Encoder-Decoder 模型:
- T5:将所有 NLU 和 NLG 任务都转换为 Seq2Seq 形式统一解决(例如,文本分类就是将文本送入 Encoder,然后 Decoder 生成文本形式的标签)。T5 通过 MLM 及将所有 SuperGLUE 任务转换为 Seq2Seq 任务来进行预训练。最终,具有 110 亿参数的大版本 T5 在多个基准上取得了最优性能。
- BART:同时结合了 BERT 和 GPT 的预训练过程。将输入句子通过遮盖词语、打乱句子顺序、删除词语、文档旋转等方式破坏后传给 Encoder 编码,然后要求 Decoder 能够重构出原始的文本。这使得模型可以灵活地用于 NLU 或 NLG 任务,并且在两者上都实现了最优性能。
- M2M-100:语言对之间可能存在共享知识可以用来处理小众语言之间的翻译。M2M-100 是第一个可以在 100 种语言之间进行翻译的模型,并且对小众的语言也能生成高质量的翻译。该模型使用特殊的前缀标记来指示源语言和目标语言。
- BigBird:由于注意力机制 O(n2) 的内存要求,Transformer 模型只能处理一定长度内的文本。 BigBird 通过使用线性扩展的稀疏注意力形式,将可处理的文本长度从大多数模型的 512 扩展到 4096,这对于处理文本摘要等需要捕获长距离依赖的任务特别有用。
小结
通过本章,相信你已经对 Transformer 模型的定义和发展有了大概的了解,接下来就可以根据自己的需要对感兴趣的 Transformer 模型进行更深入地探索。
参考
[1] HuggingFace 在线教程
[2] Lewis Tunstall 等人. 《Natural Language Processing with Transformers》
文章来源 transformers.run
- LinkAI工作流(WorkFlow) 智能体Agent
- 完美绕过激活解锁信号插卡,GusActivatorPro A12+发布!
- 能在手机上跑的开源小模型 H2O-Danube3
- 大模型的注意力机制
- 聚合多模型平台 AskManyAI